之前在 V 站上看到一个帖子,内容是楼主想抓取数据的网站做了参数加密,不知如何解密。刚好最近有点空闲时间,可以尝试解密一下网页参数,而且很久没练手了。
文中会介绍几种分析技巧,需要一点前端知识(总感觉在前端做防爬没什么意义,因为源码都是公开的)。文末附上爬虫 Demo 验证,虽然对于这个案例来说使用 Selenium 可能才是合适的解决方法,但暴力破解才是男人的浪漫! ...嗯本文的重点只是在于分析解密的过程。有些图片因代码过长未包含在内,意会即可。
1. 一夫当关 - XHR Breakpoints
网站是七麦数据。我们要抓取的内容是页面上的 App Store 排行榜数据。
通过分析网络请求我们可以发现,榜单数据是通过 Ajax 请求来获取的。返回的数据格式是明文 Json。
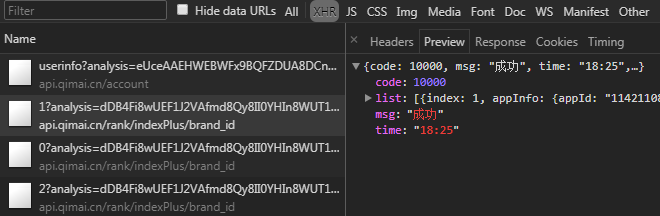
请求参数如下:
analysis: dDB4Fi8wUEF...(太长,略)
brand: all
country: cn
device: iphone
genre: 36
date: 2018-05-14
page: 1
各个参数所代表的含义都较为易懂,除了 analysis。猜测是一个经过 Base64 编码后的加密参数,事实上的确如此,隔一段时间再利用相同的 analysis 提交请求时会被拒绝。
要解密参数,只能去看 JS 的加密代码。我们需要查看是哪部分的 JS 代码发起了请求,一般的方法是点击请求列表的 Initiator 跳转到代码部分。
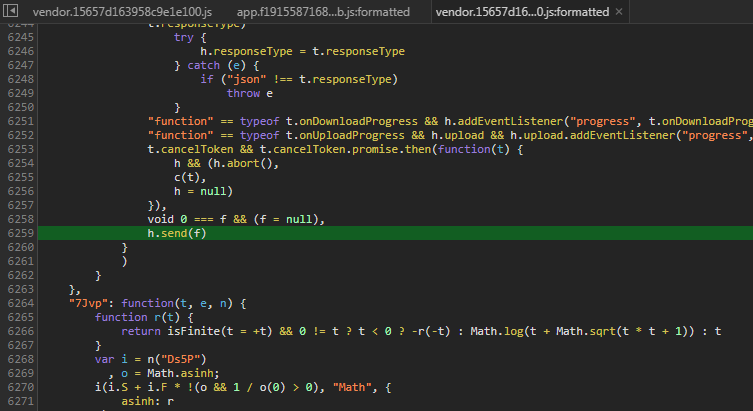
不过我更推荐另一种方法:添加 XHR Breakpoints 拦截请求。这样有两个好处,一是可以直接观察代码上下文的变量在发出请求前的数值,二是方便直接调试。此处填入 URL 包含的关键词 indexPlus
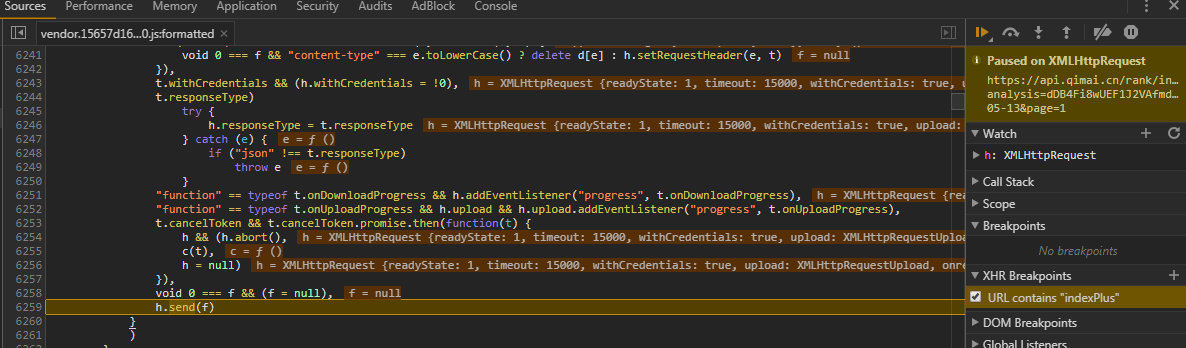
我们也可以在 Watch 处添加变量 h 进行观察,得知 h 是一个 XHR 对象。
然后再来看代码……写得乱七八糟的是什么鬼!
2. 穿针引线 - Module Require
为了应对 Web 应用越来越复杂的趋势,前端趋向模块化开发,各种自动化构建工具成为必不可少的开发利器。
跳蚤大神说得好呀,若想真正掌握爬虫技术,就要了解一个网站是怎样构建起来的。在此意义上,学习爬虫所需的前置知识还挺多的。
来观察这堆 JS 中的一段代码。
"7O1s": function(t, e, n) {
var r = n("DIVP")
, i = n("XSOZ")
, o = n("kkCw")("species");
t.exports = function(t, e) {
var n, a = r(t).constructor;
return void 0 === a || void 0 == (n = r(a)[o]) ? e : i(n)
}
},
"7UMu": function(t, e, n) {
var r = n("R9M2");
t.exports = Array.isArray || function(t) {
return "Array" == r(t)
}
},
"7gX0": function(t, e) {
var n = t.exports = {
version: "2.5.5"
};
"number" == typeof __e && (__e = n)
},
虽然代码经过了混淆,但是依然可以看出类似 7O1s 之类的随机字符串是模块名称,而 var r = n("DIVP") 即引入模块,正常的写法可能是 import a from 'b' 或者 const a = require('b')。
这里发起 Ajax 请求的函数很可能只是一个被封装了的模块供整个项目调用,粗略看一下函数代码也没有发现计算加密的部分。
针对这种模块化开发,一个逆向的思路是,只要查看该模块被引用的情况,不断向上追溯,总能找到最初发起请求和加密的函数。
将网站所有 JS 文件拷贝到本地,检索断点所在的模块名 7GwW
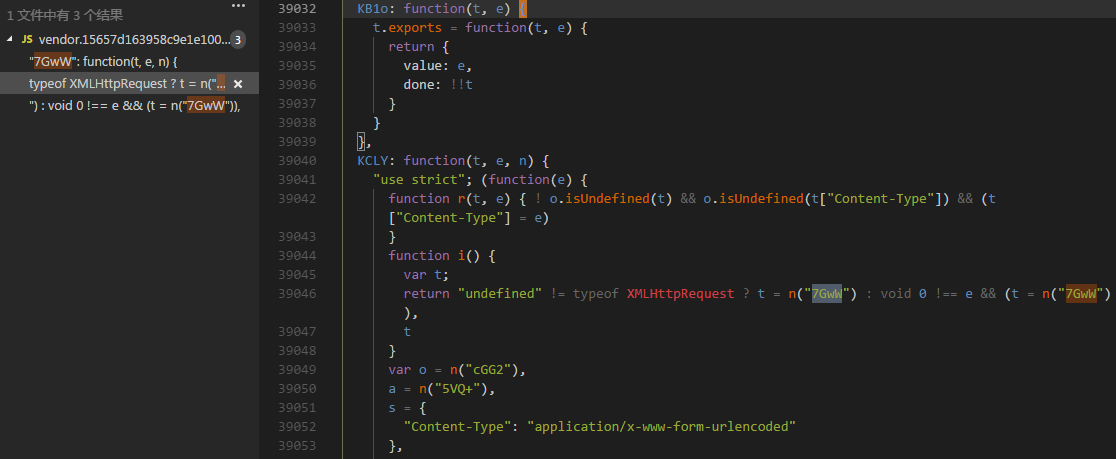
得知其由模块 KCLY 引入,接着检索 KCLY
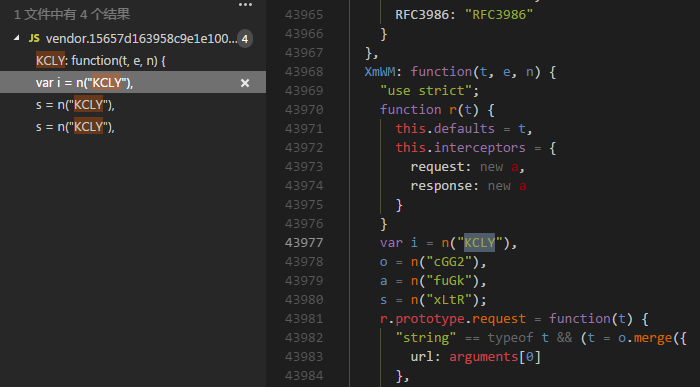
得知其有三个模块引入,不怕,我们先选第一个XmWM继续检索,如果没找到再回来
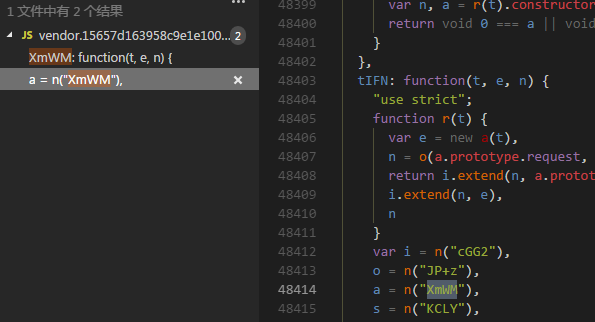
得知其由模块 tIFN 引入,继续检索,由mtWM引入,继续检索
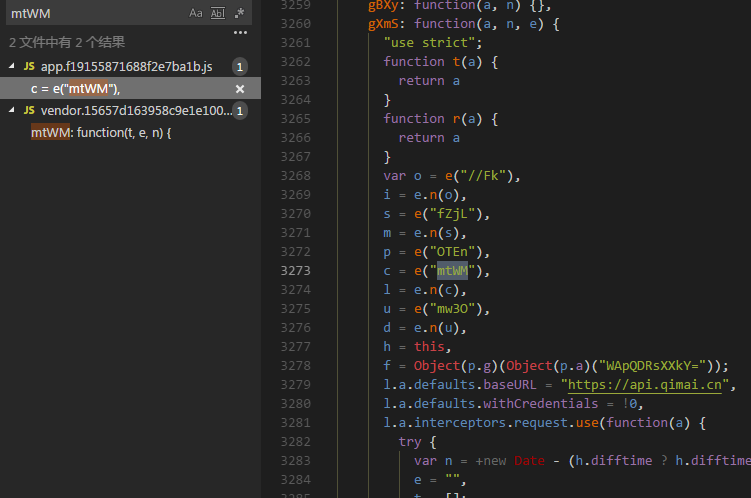
得出最终结果,是由模块 gXmS 组装的请求参数。
只要找到组装请求的代码,分析过程就算完成了一半。
3. 顺藤摸瓜 - Call Stack
可能有人要抱怨了,感觉这样查找好麻烦呀,有没有更简便的方法?
当然有。在理解了第二点分析的模块化组织代码的原理后,我们可以使用更简便的方法——Call Stack。
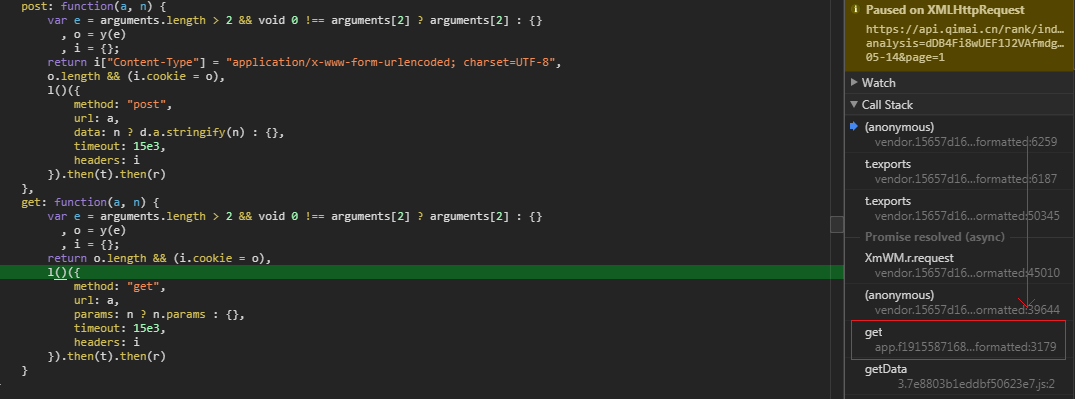
如图,通过从上至下依次查看调用栈上的代码,检查一下其所在的模块是否是要查找的目标。
get 方法即是模块 gXmS 中的函数。需要注意的是,此方法在模块的末尾,如果不细心可能会错过。
4. 偷天换日 - Hijack The Response
先在目标模块 gXmS 下个断点吧
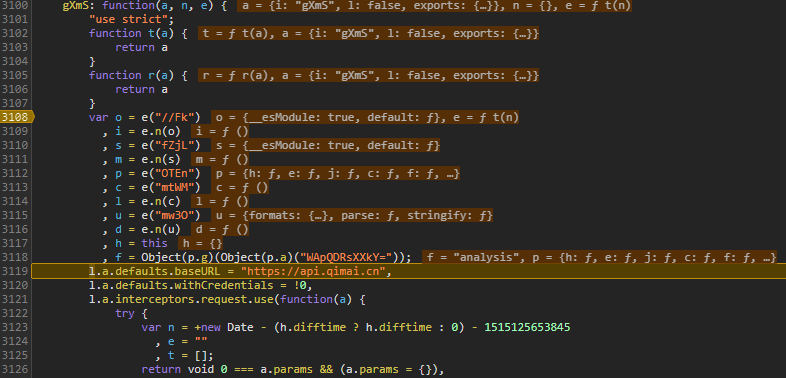
可以看到虽然变量 f 被很机智地用 Base64 重新编码了(不完全是,还有个解密函数,注意这里的 p.g 和 p.a),但是在调试器下其解码值 analysis 很容易暴露。
不过重点还是在 l.a.interceptors.request.use 的那行,里面是完整的参数组装过程,附这一段代码:
l.a.interceptors.request.use(function(a) {
try {
var n = +new Date - (h.difftime ? h.difftime : 0) - 1515125653845
, e = ""
, t = [];
return void 0 === a.params && (a.params = {}),
m()(a.params).forEach(function(n) {
if (n == f)
return !1;
a.params.hasOwnProperty(n) && t.push(a.params[n])
}),
t = t.sort().join(""),
t = Object(p.d)(t),
t += "@#" + a.url.replace(a.baseURL, ""),
t += "@#" + n,
t += "@#1",
e = Object(p.d)(Object(p.g)(t)),
-1 == a.url.indexOf(f) && (a.url += "?" + f + "=" + encodeURIComponent(e)),
a
} catch (a) {}
}, function(a) {
return i.a.reject(a)
}),
代码被用逗号运算符精简了。由于 Chrome 调试器的单步执行是以表达式为单位,因此这里我们无法对重要的变量 t 的每一步转换进行观察调试。
我们需要对代码进行修改,然后让浏览器运行修改后的代码。方法是劫持 JS 文件。
具体手段有很多种,比如 Nginx 反代,Fiddler 等。在此我选择 ReRes 插件,用法很简单就不具体介绍了。
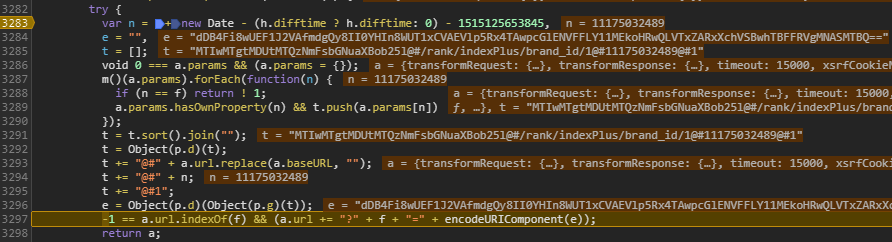
劫持后,我们可以随意更改代码以方便输出获取我们想要的信息,如下图我加了一个 v1 中间变量。
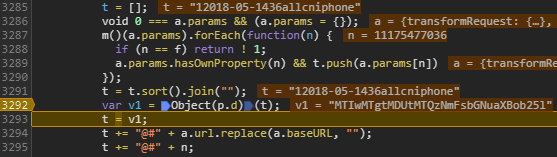
通过单步调试后,得出组装的过程,大致步骤如下:
- 设置一个时间差变量
- 提取查询参数值(除了 analysis)
- 排序拼接参数值字符串并 Base64 编码
- 拼接自定义字符串
- 自定义加密后再 Base64 编码
- 拼接 URL
那么如何得知自定义加密函数和 Base64 编码函数?
通过这一行 var v1 = Object(p.d)(t); 我们可得知 p.d 是 Base64 编码函数,因为单步调试时可观察到变量 t 经过这行代码后被编码。
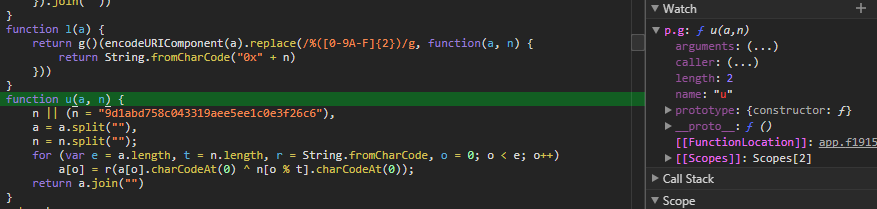
然后看这一行 e = Object(p.d)(Object(p.g)(t));,我们已知 p.d 是 Base64 编码函数,那么 p.g 就是一个未知函数。需要找到 p.g 的函数本体。
在 Watch 一栏添加 p.g,点击 FunctionLocation 的值,即可跳转到该函数。其实 p.g 同时也是一个解密函数,异或运算经常被用来加解密。
5. 东搜西罗 - Searching
这里再多说一点技巧。由于模块化开发,可能会引用到第三方库的模块,因此我们可以利用模块中的一些附带字符串在网上搜索也许会得到额外的信息。
搜索相关错误信息后得知网页用了 Node.js 的 Buffer 模块。
进一步分析还发现引入 Buffer 模块的目的之一就是为了方便 Base64 编码。
6. 一锤定音 - Crawler
最后写一个50行的简单爬虫来验证分析,抓取 iPhone 免费榜单。
#!/usr/bin/env python3
import time
import json
import base64
import requests
from urllib.parse import urlencode
headers = {
"Accept": "application/json, text/plain, */*",
"Referer": "https://www.qimai.cn/rank",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:57.0) Gecko/20100101 Firefox/59.0"
}
params = {
"brand": "all",
"country": "cn",
"date": "2018-05-14",
"device": "iphone",
"genre": "36",
"page": 1
}
# 自定义加密函数
def encrypt(a, n="9d1abd758c043319aee5ee1c0e3f26c6"):
s = list(a)
n = list(n)
sl = len(s)
nl = len(n)
for i in range(0, sl):
s[i] = chr(ord(s[i]) ^ ord(n[i % nl]))
return "".join(s)
def main():
# iPhone 免费榜单
# 提取查询参数值并排序
s = "".join(sorted([str(v) for v in params.values()]))
# Base64 Encode
s = base64.b64encode(bytes(s, encoding="ascii"))
# 时间差
t = str(int((time.time() * 1000 - 1515125653845)))
# 拼接自定义字符串
s = "@#".join([s.decode(), "/rank/indexPlus/brand_id/1", t, "1"])
# 自定义加密 & Base64 Encode
s = base64.b64encode(bytes(encrypt(s), encoding="ascii"))
# 拼接 URL
params["analysis"] = s.decode()
url = "https://api.qimai.cn/rank/indexPlus/brand_id/1?{}".format(urlencode(params))
# 发起请求
res = requests.get(url, headers=headers)
j = json.loads(res.text)
print(j)
if __name__ == '__main__':
main()
EOF